









Отношение к нейросетям в корпоративной среде прошло занятный цикл. Сначала был страх полной потери рабочих мест. Затем наступило закономерное разочарование от выдуманных судебных прецедентов и нелепых ошибок ранних чат-ботов. Сейчас мы находимся на этапе абсолютно прагматичного внедрения. Искусственный интеллект не заменяет специалиста по праву. Однако специалист с грамотно настроенными алгоритмами начинает критически обходить коллегу, который по старинке вычитывает сотни страниц с маркером в руке.
Сегодня языковые модели способны за секунды находить противоречия в многостраничных соглашениях, предлагать безопасные формулировки и оценивать риски сделки. Но чтобы этот инструмент приносил пользу, а не убытки, нужно четко понимать механику его работы. Нейросеть это не электронный мозг и не справочник по законодательству. Это математическая модель, предсказывающая наиболее вероятное следующее слово. И именно в этом кроется как ее невероятная сила, так и главная опасность.
Как алгоритмы читают ваши документы
Для начала стоит забыть о попытках скормить сложный юридический кейс базовой версии бесплатного чат-бота. Стандартные модели обучаются на огромном массиве данных из интернета. Они знают всего понемногу: от рецептов пирогов до квантовой физики. В их «голове» Гражданский кодекс соседствует с форумами автолюбителей. Поэтому без правильного контекста машина будет выдавать усредненный, поверхностный ответ.
Реальная магия начинается, когда вы используете модели с большим контекстным окном (до 1 миллиона токенов) или применяете архитектуру RAG с интеграцией агентных систем. Аббревиатура расшифровывается как генерация с дополненной выборкой. Вы загружаете в систему конкретную базу данных. Это могут быть внутренние регламенты вашей компании, свежая судебная практика или архив договоров за прошлый год. Нейросеть сначала ищет нужный фрагмент в ваших достоверных источниках, а уже потом формулирует ответ на основе найденного. Это снижает вероятность бреда практически до нуля.
Современные флагманские модели могут держать в памяти тысячи страниц текста одновременно. Вы можете загрузить PDF-файл с договором аренды коммерческой недвижимости на восемьдесят страниц и задать точечный вопрос. Машина проанализирует весь объем и выдаст выжимку.
Анализ договоров и поиск уязвимостей
Самый частый и самый окупаемый сценарий использования ИИ в бизнесе заключается в проверке входящих документов. Контрагенты часто присылают свои шаблоны соглашений, которые составлены исключительно в их интересах. Искать там подвохи вручную долго и утомительно.
Как выстроить процесс проверки:
- Обезличивание. Это ПЕРВОЕ И ГЛАВНОЕ правило. Перед загрузкой документа в сторонний облачный сервис удалите из него названия компаний, имена генеральных директоров, суммы сделок и точные адреса. Замените их условными обозначениями вроде «Сторона 1» и «Объект».
- Загрузка и постановка задачи. Не просите систему просто «проверить договор». Задавайте узкие рамки. Попросите найти все условия, при которых контрагент может расторгнуть соглашение в одностороннем порядке без штрафных санкций. Или поручите выявить пункты, где ваша ответственность не ограничена суммой контракта.
- Поиск скрытых ссылок. Нейросети отлично справляются с распутыванием сложных цепочек условий. Часто в пункте 3.4 написано, что оплата производится согласно приложению 2, а в приложении 2 есть отсылка к внутреннему регламенту контрагента, который вы вообще не видели в глаза. Машина подсветит такие слепые зоны моментально.
Генерация документов с нуля
Синдром чистого листа забирает огромное количество времени. Когда нужно составить нестандартное соглашение о неразглашении или специфический договор подряда, ИИ выступает идеальным стартовым ускорителем. Он не напишет идеальный финальный вариант, но создаст крепкий скелет, который останется только адаптировать.
Секрет качественной генерации кроется в итеративном подходе. Не пытайтесь получить весь документ одним запросом. Действуйте по шагам.
Сначала попросите составить подробную структуру будущего договора на основе ваших вводных данных. Опишите суть сделки максимально подробно: кто заказчик, кто исполнитель, в чем специфика услуги, какие сроки, как происходит приемка работ. Когда нейросеть выдаст оглавление из пятнадцати пунктов, внимательно прочитайте его. Добавьте недостающие разделы, уберите лишние.
Только после утверждения структуры просите алгоритм расписать каждый пункт детально, один за другим. Просите использовать строгий деловой стиль и опираться на актуальное законодательство. Полученные блоки текста собираются в текстовом редакторе и шлифуются человеком.
Обзор рынка инструментов: что использовать в реальности
Выбор инструмента напрямую зависит от ваших технических возможностей и готовности решать вопросы с доступом. На рынке сейчас есть четкое разделение на глобальных лидеров и мощные локальные решения.
Если говорить о работе со сложными текстами, логикой и нюансами формулировок, безусловным лидером на данный момент является семейство моделей Claude 4.6 (Sonnet и Opus) от компании Anthropic. Эти модели демонстрируют феноменальное понимание контекста, мощные агентные возможности и пишут очень естественным языком без картонных канцелярских штампов. Однако для регистрации и оплаты подписки потребуется карта иностранного банка, а сам сервис в нашем регионе работает только при смене IP-адреса.
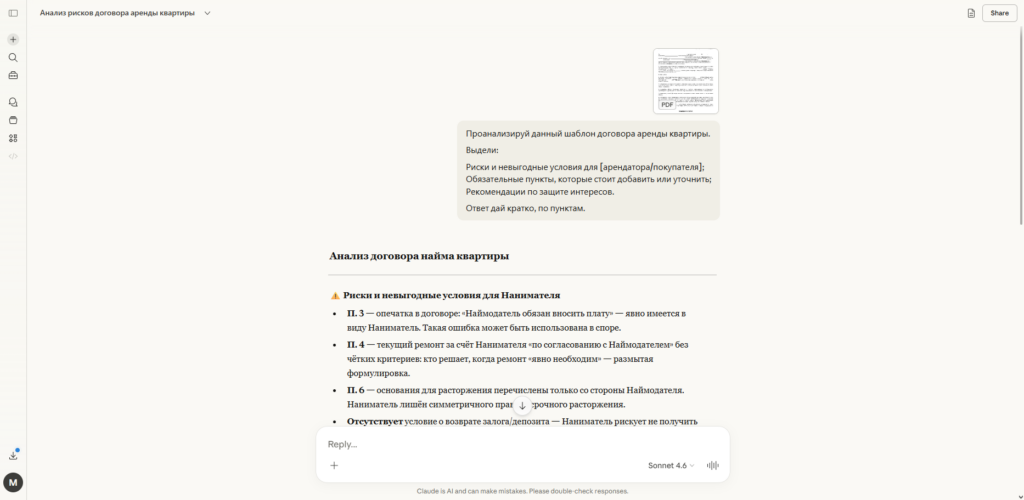
Модели GPT-5.4 от OpenAI сохраняют свои позиции. Платная версия ChatGPT отлично справляется с анализом огромных таблиц, структурированием данных и написанием кода для автоматизации процессов. Нюансы доступа здесь точно такие же, как и у предыдущего сервиса: нужны зарубежные платежные инструменты.
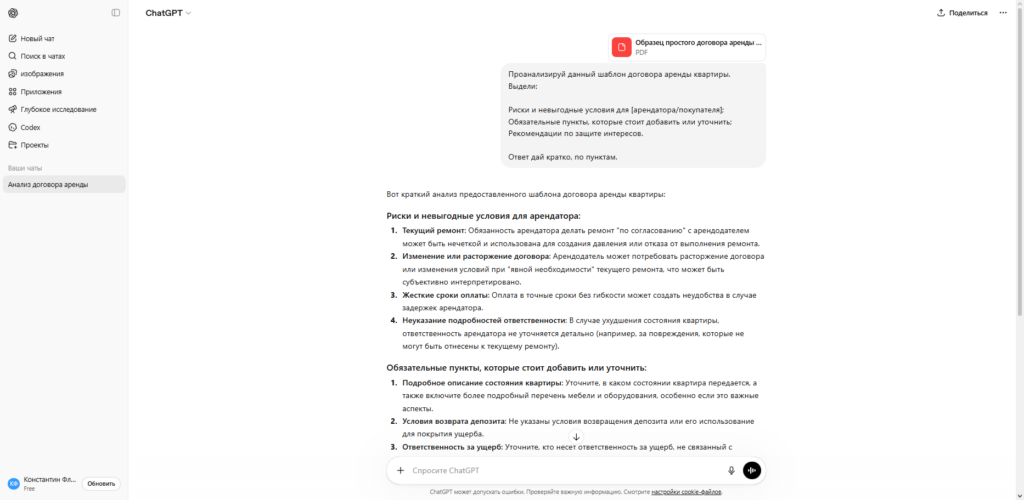
Российский рынок нейросетей развивается стремительно и предлагает отличные альтернативы. Главное преимущество отечественных разработок кроется в изначальном обучении на массивах текстов на русском языке, включая нормативно-правовую базу РФ. Модели YandexGPT 5 и GigaChat Ultra принимают оплату картами российских банков, не требуют сложных настроек сети и легко интегрируются в корпоративные системы через API.
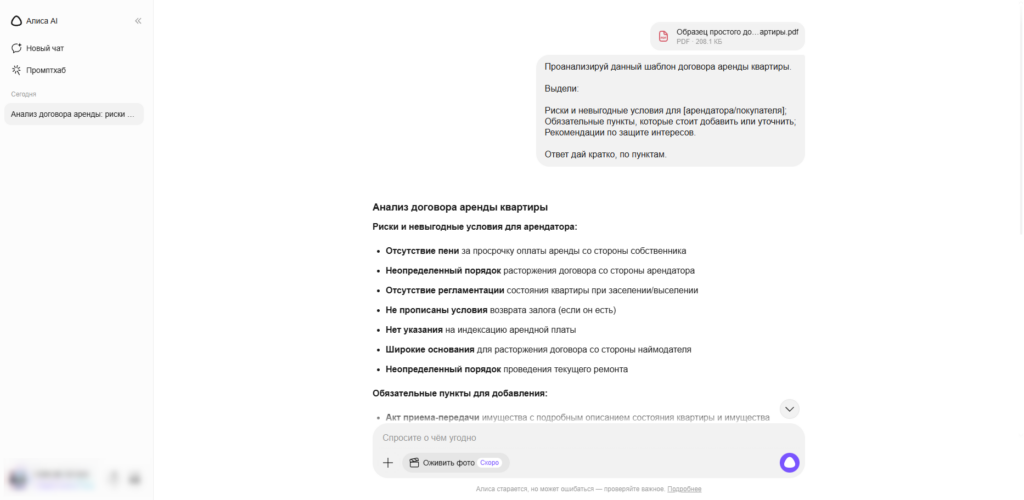
Для рутинных задач по генерации базовых договоров или написанию официальных писем локальных решений уже более чем достаточно. Кроме того, использование российских API часто становится единственным легальным выходом для компаний с жесткой политикой информационной безопасности, где передача данных на зарубежные серверы строго запрещена.
Также стоит упомянуть специализированный LegalTech. Крупнейшие справочно-правовые системы уже встраивают функции на базе искусственного интеллекта в свои продукты. Это позволяет искать ответы на сложные правовые коллизии не по ключевым словам, а задавая вопросы на естественном языке, причем алгоритм будет искать ответ исключительно в проверенной базе законов и судебных решений.
Риски, галлюцинации и юридическая ответственность
Технологии выглядят настолько убедительно, что вызывают ложное чувство безопасности. И это главная ловушка для любого специалиста. В США уже прогремело несколько громких скандалов, когда адвокаты приносили в суд документы, подготовленные чат-ботом. Проблема заключалась в том, что ИИ выдумал судебные прецеденты, номера дел и даже цитаты судей, которых никогда не существовало.
Почему это происходит? Потому что генеративная сеть не ищет информацию в базе данных. Она генерирует текст буква за буквой. Если алгоритм не знает ответа, он с огромной долей вероятности придумает максимально правдоподобно звучащую ложь. Он сгенерирует номер статьи, назовет вымышленный федеральный закон и подведет под это стройную логическую базу.
ВСЕГДА проверяйте факты, даты, номера статей и ссылки на законы, которые выдает машина.
Второй критический риск связан с конфиденциальностью. Когда вы отправляете некий текст в публичный веб-интерфейс популярного бота, вы фактически дарите эту информацию разработчикам модели. Эти данные могут быть использованы для дообучения алгоритмов. Если вы загрузите туда договор о готовящемся слиянии компаний с реальными названиями и цифрами, завтра эти данные могут случайно всплыть в ответе другому пользователю. Для работы с чувствительной коммерческой тайной необходимо использовать закрытые корпоративные решения, где политика конфиденциальности гарантирует неиспользование ваших данных для тренировки моделей.
Как правильно формулировать запросы (Промптинг)
Качество ответа системы на девяносто процентов зависит от качества вашего запроса. Забудьте короткие фразы в стиле поисковиков. Общайтесь с машиной как с умным, но очень буквальным стажером. Рабочий запрос должен состоять из четырех обязательных элементов.
- Роль. Задайте алгоритму профессиональную оптику. Начните запрос с фразы: Действуй как старший юрисконсульт компании, специализирующейся на IT-разработке и защите интеллектуальной собственности.
- Контекст. Объясните ситуацию. Например: Мы планируем нанять команду независимых разработчиков для создания мобильного приложения. Нам нужно передать им доступ к нашему исходному коду, но полностью защитить себя от утечек и копирования наших алгоритмов.
- Задача. Сформулируйте четкое поручение. Напиши проект соглашения о неразглашении конфиденциальной информации. Особое внимание удели разделу ответственности за передачу кода третьим лицам.
- Формат. Укажите, как должен выглядеть результат. Разбей текст на логические разделы. Сложные юридические конструкции сопровождай кратким пояснением для неспециалистов. Выдай результат в виде нумерованного списка.
Соединив эти элементы вместе, вы получите детализированный и полезный ответ, который потребует минимальной правки.
Внедрение в реальную работу
Технологии меняют подход к работе с документами прямо сейчас. Сопротивляться этому процессу бессмысленно, гораздо выгоднее возглавить его в своей практике. Начните с малого. Не пытайтесь сразу автоматизировать сложнейшие корпоративные сделки.
Возьмите обезличенный типовой договор, который вы хорошо знаете. Загрузите его в систему и попробуйте найти в нем уязвимости с помощью алгоритма. Сравните результаты машины с вашим собственным опытом. Попробуйте сгенерировать шаблон ответа на претензию недовольного клиента. Чем больше вы будете экспериментировать с промптами и контекстом, тем быстрее нащупаете те зоны, где искусственный интеллект реально экономит вам часы рутинной работы.

